
我們昨天介紹了 Spotify 的舊系統,以及它存在的一些問題。那今天我們就來看看他們是怎麼解決的吧!
為了解決這個問題,Spotify 開發了一套基於 Google Cloud 技術的新系統,新系統旨在提高事件處理的速度、可靠性和彈性,與舊系統相比,它實現了更低的延遲和更高的靈活性。
系統架構如下圖所示:
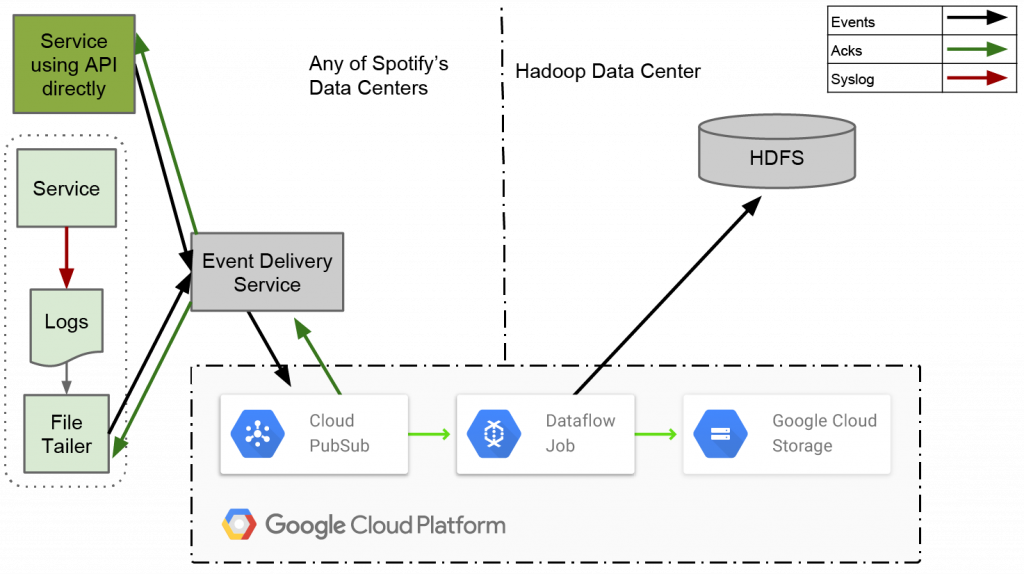
圖片來源:https://engineering.atspotify.com/2016/03/spotifys-event-delivery-the-road-to-the-cloud-part-ii/
主要分為幾個步驟:
關於各個儲存空間的小補充
如果不熟悉各種儲存空間的朋友,可以來看這邊的簡單小介紹。
HDFS 跟 Hive 都是 local 的儲存系統,HDFS 是 Hadoop 生態系統的核心存儲系統,專為大規模數據設計。它會將數據分散存儲在多個節點上,確保高可用性(high availability)和容錯性。而 Hive 是基於 Hadoop 的數據倉庫,將結構化數據儲存成表格形式,並提供類似 SQL 的查詢語言。
不過這兩個都是 local 的服務,Spotify 想要逐步把資料搬到 cloud 上,HDFS 對應的會是 Google Cloud Storage (GCS) 或 AWS S3,而 Hive 會比較類似於 BigQuery 或 Amazon Redshift。
接著,我們來講解幾個關鍵步驟和優勢吧。
Spotify 的新系統不會每個小時才處理一次資料,而是利用 Google Cloud Pub/Sub 和 Dataflow 的串流處理能力,讓資料一從 Pub/Sub 收到之後就被處理,不斷地持續處理資料,並以串流方式將資料寫入每小時的區塊中。
這個新系統可以改善舊系統的延遲問題,避免像舊系統可能會有延遲時間長達兩到三個小時的問題。
為了避免不同類型事件之間的干擾,新系統為每種事件類型分配了獨立的 Pub/Sub 主題(Topic),進而優化 ETL 作業效率,縮短處理時間。目前已經能處理超過 1800 種不同的事件類型。
Cloud Pub/Sub 提供了七天的訊息保存期,保證事件的持久性,即使下游的 Hadoop 叢集出現故障,事件資料也不會丟失。
Dataflow 是 Google Cloud 提供的服務,在 Spotify 的 ETL 作業中扮演非常重要的角色。它被用來構建 ETL 作業,負責將儲存在 Cloud Pub/Sub 中的事件資料匯出至 HDFS 或 Cloud Storage 中。
建構資料處理 pipelines:Dataflow 提供一個框架,讓 Spotify 的工程師可以利用程式碼來定義資料處理的步驟,包含從 Pub/Sub 讀取資料、轉換資料格式、以及將資料寫入 HDFS 或 Cloud Storage。
串流資料處理:Dataflow 支援串流資料處理模式,讓 Spotify 可以持續不斷地處理從 Pub/Sub 收到的事件資料,並即時寫入到儲存系統中。這種串流處理方式大幅降低資料處理的延遲,解決舊系統的每小時一次處理的問題。
Windowing 功能:Spotify 的 ETL 作業使用 Dataflow 的 windowing 概念,根據事件時間戳記將資料劃分到每小時的區塊中。每個區塊由事件時間戳記決定,例如,時間戳記落在 08:00:00 到 08:59:59 的事件將被寫入到 08:00:00 的區塊中。這對於處理無序的資料流非常有用,可以確保資料按照正確的時間順序被處理。
Watermark 機制:Dataflow 的 watermark 是一種基於事件時間戳記的機制,用於估計特定時間窗口內所有事件都已到達的時間點。機制可以協助判斷特定時間窗口內的所有事件是否都已到達,進而更精確地控制資料處理流程,例如關閉已完成的區塊、處理遲到的資料等。
Early Trigger 和 Late Trigger:
ETL 作業還會使用 early trigger 和 late trigger 來控制區塊的建立和發布。Early trigger 允許在區塊關閉之前定期釋出資料,降低延遲。而 Late trigger 則用於處理遲到的資料,確保所有資料最終都能被寫入到正確的區塊中。
昨天有提到 Spotify 的舊系統在處理資料延遲時非常不理想,需要手動停止後續的 ETL 任務,而新系統使用的 Dataflow 可以很有效地解決這個問題。
ETL 作業使用 Dataflow 的 watermark 機制來判斷何時關閉一個 window,當 watermark 超過一個區塊的結束時間時,該區塊就會被關閉,之後到達的任何資料都會被視為遲到資料。
對於遲到的資料,ETL 作業會將其寫入當前的時間區塊中,而不是回填到原始區塊,以避免資料不一致。例如,如果一個事件的時間戳記是 08:55:00,但它在 09:10:00 才到達,它會被寫入到 09:00:00 的區塊中。藉由這個方式,原本的區塊就不需要等待遲到的資料抵達,可以流暢地進行 ETL 任務,也不會造成資料不一致的問題。
以上就是 Spotify 新系統的架構介紹,他們借力於 Google Cloud 的 Pub/Sub 和 Dataflow,打造出一個非常穩健又有效率的的新系統。
為了確保新系統能處理預期的資料量,他們進行了一系列的嚴格測試。結果顯示,新系統能夠每秒處理 200 萬條訊息,而現有服務每秒約有 70 萬個事件,遠低於新系統能夠處理的。顯示新系統不僅能夠應付當前的負載需求,還為未來可能的增長提供了充足的空間。
並且,新系統在處理 200 萬條訊息時,沒有服務效能下降,也沒有收到來自 Pub/Sub 後端的伺服器錯誤,在傳輸過程更沒有顯著的延遲。這個測試顯示,系統在高流量下仍能保持穩定的效能。
這個就是 Spotify 新事件傳輸系統的完整介紹啦!希望大家覺得有趣跟有所助益。
我們花了兩天來認識 Spotify Data Platform 的前世跟今生,現在 Spotify 已經可以不斷地將各式各樣的用戶行為都寫入他們的 Big Query,以提供給全公司的人使用了。
他們整間公司都可以使用這個 data platform,只要定義好 event schemas,不需要煩惱後續的管理服務。目前有超過 1800 個不同的 event types 被送過來,代表各式各樣用戶的行為資訊。另外,他們每天總共約有 38000 個 data pipelines,顯示新系統是足以負荷如此龐大規模資料的能力。
新系統總算是大功告成啦!

不過事情還沒結束,記得我們之前在介紹 ML 生命週期時,有提過資料的管理和版本是很重要的嗎?Spotify 當然也很重視這點,以下是他們在意的幾件事情:
資料完整性:Spotify 非常重視資料的品質,確保資料準確、一致且可靠,因為不可靠的資料可能會導致錯誤的判斷和結論。
資料的可搜尋性:Spotify 使用 meta-data 來描述和分類其資料,使其易於搜尋和探索。使內部用戶能夠快速地找到他們需要用於分析、報告或機器學習任務的資料內容。
資料的可追溯性:Spotify 會完整紀錄資料的來源到使用地點,建立資料血緣(lineage),確保資料品質,以及有助於偵測問題。
資料存取控制:Spotify 實施非常嚴格的資料存取控制,以保護敏感資料並遵守隱私法規,只有獲得授權的個人和系統才能存取特定資料集。
監控和警報: Spotify 的資料平台包含全面的監控和警報功能,可以追蹤資料處理效能、偵測異常並向相關團隊發送通知,確保資料的可靠性,也在偵測到 data drift 或 concept drift 時,能夠即時改善。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference:

 iThome鐵人賽
iThome鐵人賽